问如何制作自己的AI配音音频

-
 黑夜品鉴师?
黑夜品鉴师?
想要制作自己的AI配音音频,可以通过以下步骤实现:
1. 选择合适的语音合成技术:目前主流的语音合成技术有WaveNet、Tacotron、DeepVoice等。可以根据自己的需求和技术熟悉程度选择合适的技术。
2. 收集并标注语音训练数据:语音合成模型需要大量的训练数据来学习语音特征。可以使用公开可用的数据集,如LJSpeech、LibriSpeech等,也可以自行采集。
3. 进行数据预处理:对采集到的语音数据进行预处理,包括音频格式转换、音频分割、噪声去除等。确保数据的质量和一致性。
4. 训练语音合成模型:使用选择的语音合成技术和预处理后的数据,训练模型。可以使用开源的深度学习框架,如TensorFlow、PyTorch等来实现。
5. 调优和优化:在训练过程中,可以根据实际效果对模型进行调优和优化。调整模型的超参数,如学习率、批大小等来提升合成音频的质量。
6. 测试和评估:训练完成后,使用一些评估指标,如语音相似度、流利度等来评估合成音频的质量。通过与真实的人类语音进行比较,不断改进和优化。
7.应用部署:将训练好的模型部署到实际应用中。根据需求,可以将模型封装成API接口,或者嵌入到移动应用或网页中,实现AI配音的功能。
制作自己的AI配音音频是一个复杂的过程,需要具备一定的机器学习和音频处理知识。合成出的音频质量可能会受到训练数据的限制,需要不断优化和改进模型。
-
 小雯雯.
小雯雯.
要制作自己的AI配音音频,有以下几个步骤:
1. 收集和准备数据:你需要收集大量的音频数据,包括人声、音乐和其他声音。这些音频应该涵盖各种语速、语调和情感。你还需要准备一个标注数据的集合,将每个音频与其对应的文本进行关联。
2. 数据预处理:在开始训练模型之前,需要对收集到的音频数据进行预处理。这包括将音频转换为数字形式,进行采样率和位深度的标准化,以及去除噪音和其他干扰。
3. 模型选择和训练:选择适合的深度学习模型,如循环神经网络(RNN)或变分自动编码器(VAE)。使用准备好的音频数据集对模型进行训练,通过训练来学习音频和文本之间的关联关系。
4. 模型优化:经过初始训练后,需要对模型进行优化,以改善其生成音频的质量。这可以通过调整模型的超参数、增加训练数据的数量或增加模型的复杂度来实现。
5. 测试和评估:使用新的文本输入来测试训练好的模型,并评估它的生成音频的质量。可以使用自动化的评估指标,如语音识别错误率(WER)或主观评估。
6. 部署和应用:一旦满意生成音频的质量,就可以将训练好的模型部署到应用程序中,供用户使用。可以通过开发自己的应用程序或使用现有的语音合成API来实现。
制作自己的AI配音音频是一个复杂的过程,需要有相关的编程和深度学习知识。如果你是初学者,建议从学习基础的音频处理和深度学习算法开始,并逐步扩展你的技能和知识。
免责声明:以上整理自互联网,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。(我们重在分享,尊重原创,如有侵权请联系在线客服在24小时内删除)




-
问英文配音脏句是什么 1个回答
-
问配音的是英文怎么说 1个回答
-
问英文配音你被爱着是什么歌 1个回答
-
问蛋仔中式英文配音怎么弄 1个回答
-
问绝美英文配音演员是谁呢 1个回答
-
问跳舞配音乐英文版有哪些 1个回答









-

-
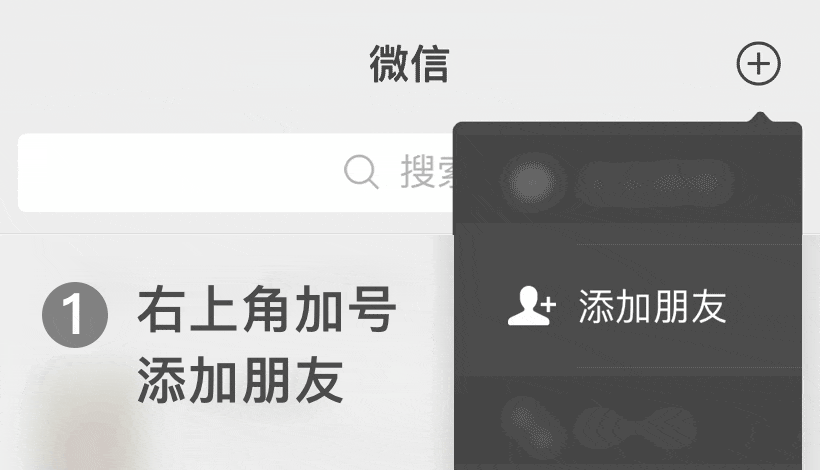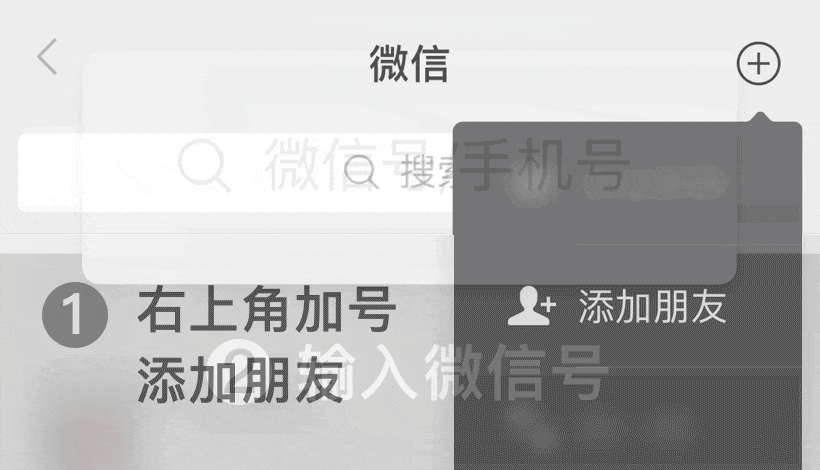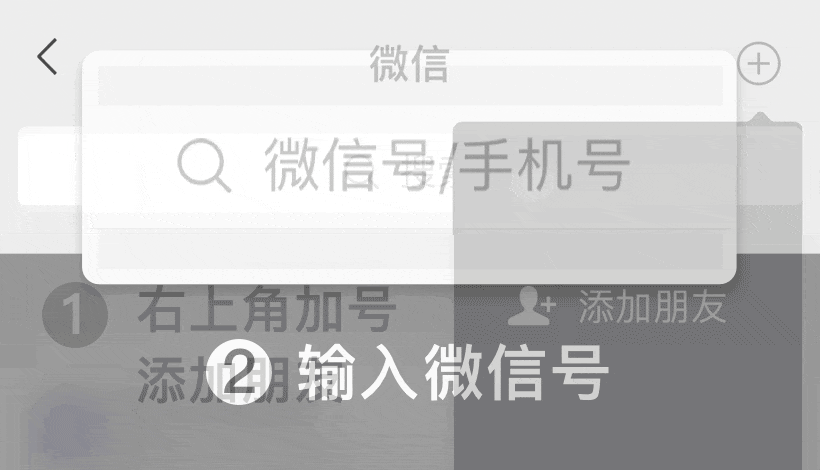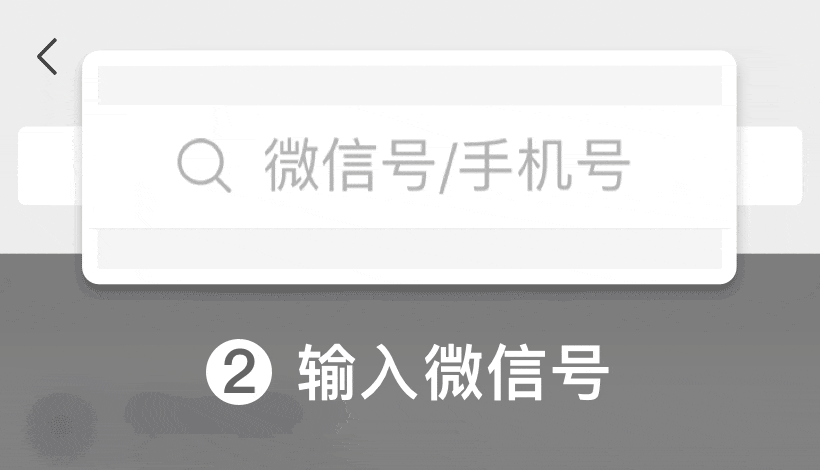
关注【客服微信】
抢先听最新案例,新客礼包等你拿!