问自动配音是怎么做的

-
 白小纯的白
白小纯的白
自动配音是一种利用计算机技术将文本转化为语音的过程。它通常包括以下步骤:
1. 文本处理:首先,自动配音系统会对输入的文本进行处理,将其分割成单词或音节,并确定每个单词的发音。
2. 文本转音素:接下来,系统会将文本中的每个单词或音节转化为对应的音素,即语音的基本单位。音素是语音的最小可区分单位,不同的语言和方言可能有不同的音素库。
3. 音素合成:系统会根据每个音素的发音规则和上下文信息,通过合成技术生成对应的音频片段。这些音频片段可以是储存在系统中的预先录制的声音库中已有的声音片段,或者是由算法生成的合成音。音素合成技术可以基于规则、统计学或深度学习等不同的方法。
4. 音频拼接:生成的音频片段会按照文本的顺序进行拼接,形成连续的语音流。在拼接过程中,系统可能会根据需要进行音量、音调、语速等参数的调整,以确保语音的自然流畅。
5. 音频后处理:最后,系统可能会对生成的语音进行后处理,例如去除噪音、增加声音效果、调整音量平衡等。这样可以提高语音的质量和可听性。
需要注意的是,自动配音的质量取决于语音合成算法的性能和语音库的质量。随着计算机技术的发展,自动配音系统的性能和逼真程度也在不断提高。
-
 何必有
何必有
自动配音是一种使用人工智能技术实现的语音合成技术,能够将文本自动转换成自然流畅的语音。下面是自动配音的大致步骤:
1. 文本分析:首先,系统需要对输入的文本进行分析,理解其中的语义和语法结构。这一步通常包括句子分割、词汇分割、词性标注和语义分析等。
2. 文本转音素:接下来,系统将文本转换成对应的音素序列。音素是语言中最小的音位单元,每个音素对应着一个发音。
3. 音素转声学特征:在这一步,系统将音素序列转换为声学特征。声学特征包括频谱、基频、声道特征等,这些特征描述了语音的声音和音调。
4. 声学模型训练:系统需要使用大量的语音数据和相应的文本数据进行模型训练。训练的目标是使系统能够根据输入的文本生成合适的声学特征。
5. 合成语音:根据输入的文本和训练好的声学模型,系统将生成对应的声学特征序列。然后,这些声学特征会通过声音合成器进行合成,最终产生自然流畅的语音音频。
值得注意的是,自动配音技术不仅仅适用于单个人的声音合成,还可以实现多种不同音色、语气和语言的语音合成。这是通过训练多个声学模型,每个模型对应一个不同的音色或语气。在进行文本转音素和音素转声学特征的步骤中,系统会根据所选的声学模型来生成对应的声学特征序列,从而实现不同的语音风格。
免责声明:以上整理自互联网,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。(我们重在分享,尊重原创,如有侵权请联系在线客服在24小时内删除)




-
问提纳里配音英文怎么说 1个回答
-
问主持词英文配音怎么写 1个回答
-
问湖北英文配音行业现状如何 1个回答
-
问少儿漫画英文配音怎么配 1个回答
-
问狐尼克英文配音是谁 1个回答
-
问什么英文句子好配音 1个回答









-

-
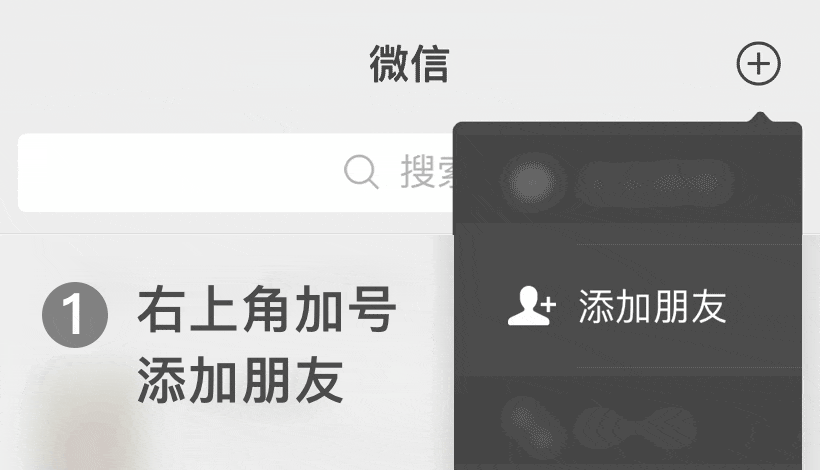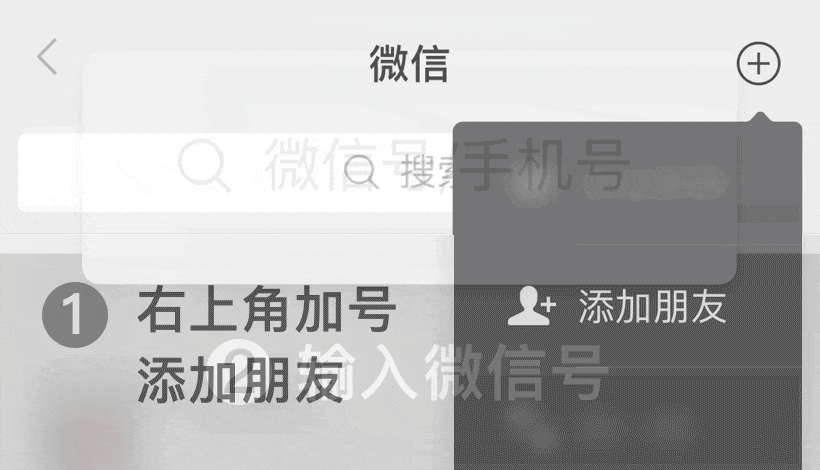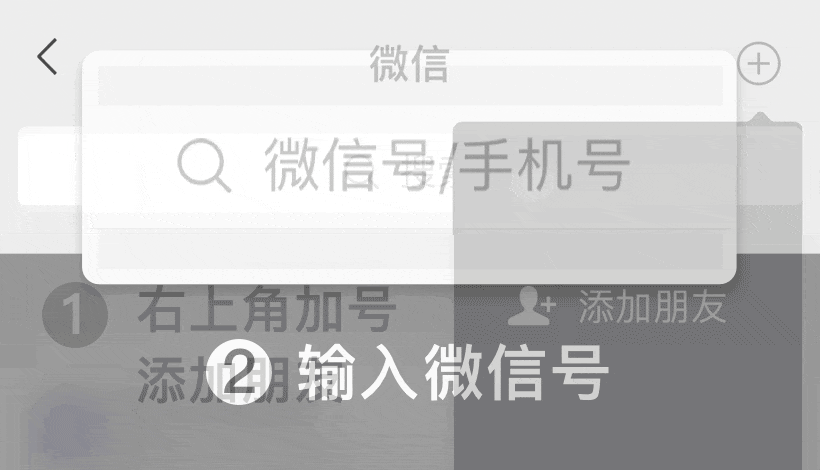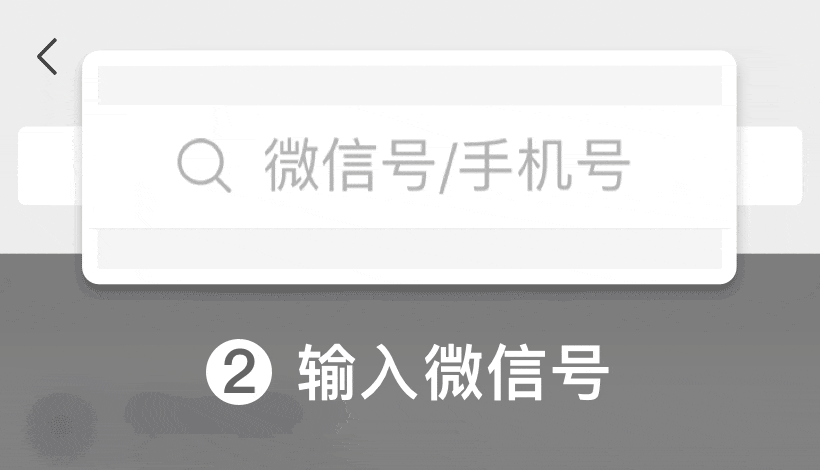
关注【客服微信】
抢先听最新案例,新客礼包等你拿!